- Published on
📝 Prompt Repetition Improves Non-Reasoning LLMs
- Authors

- Name
- Chengchang Yu
- @chengchangyu
I recently came across a surprisingly effective prompt technique and the results are wild.
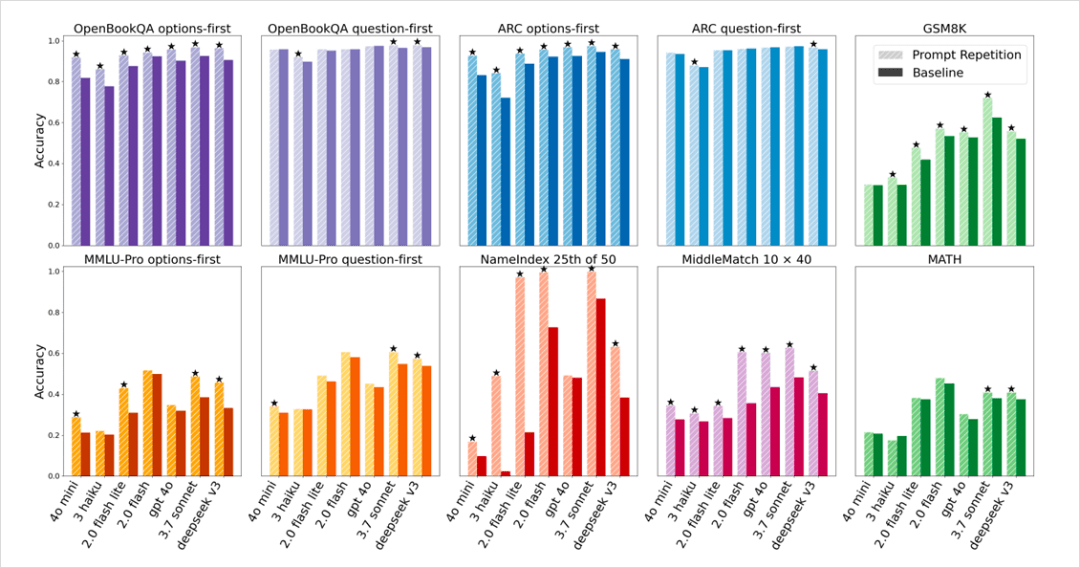
According to a new Google paper, “Prompt Repetition Improves Non-Reasoning LLMs”, simply repeating your prompt can boost accuracy in non-reasoning language models from 21.33% to 97.33% in some tasks.
📄 Paper: https://arxiv.org/pdf/2512.14982
At first, this sounds almost too abstract to be true. But the idea is incredibly simple.
In Google’s experiments across 70 different benchmark tasks, this copy-and-paste style prompt repetition:
- Outperformed the baseline in 47 tasks
- Lost zero times
- Delivered visibly large gains, with some tasks jumping from ~21% accuracy to ~97%
So why does repeating the question work?
The paper offers a very engineering-style explanation. Large language models are trained as causal language models — they generate text token by token, strictly from left to right. Each token can only “see” what came before it.
When you repeat the question (e.g., turning Q into Q1 + Q2), every token in the second copy gets full visibility into the first one. In effect, you’re giving the model a chance to look back and rethink, without changing the model or adding reasoning steps.
Sometimes, making AI “smarter” doesn’t require more complexity — just better prompt structure.