- Published on
Dropbox Architecture Deep Dive :Building a High-Frequency File Storage System at Scale 📥
- Authors

- Name
- Chengchang Yu
- @chengchangyu
Introduction
Ever wondered how Dropbox handles 600 million users, 2 billion files, and 500+ petabytes of storage while maintaining sub-100ms response times? In this deep dive, we'll explore the architectural decisions that power one of the world's most successful cloud storage platforms.
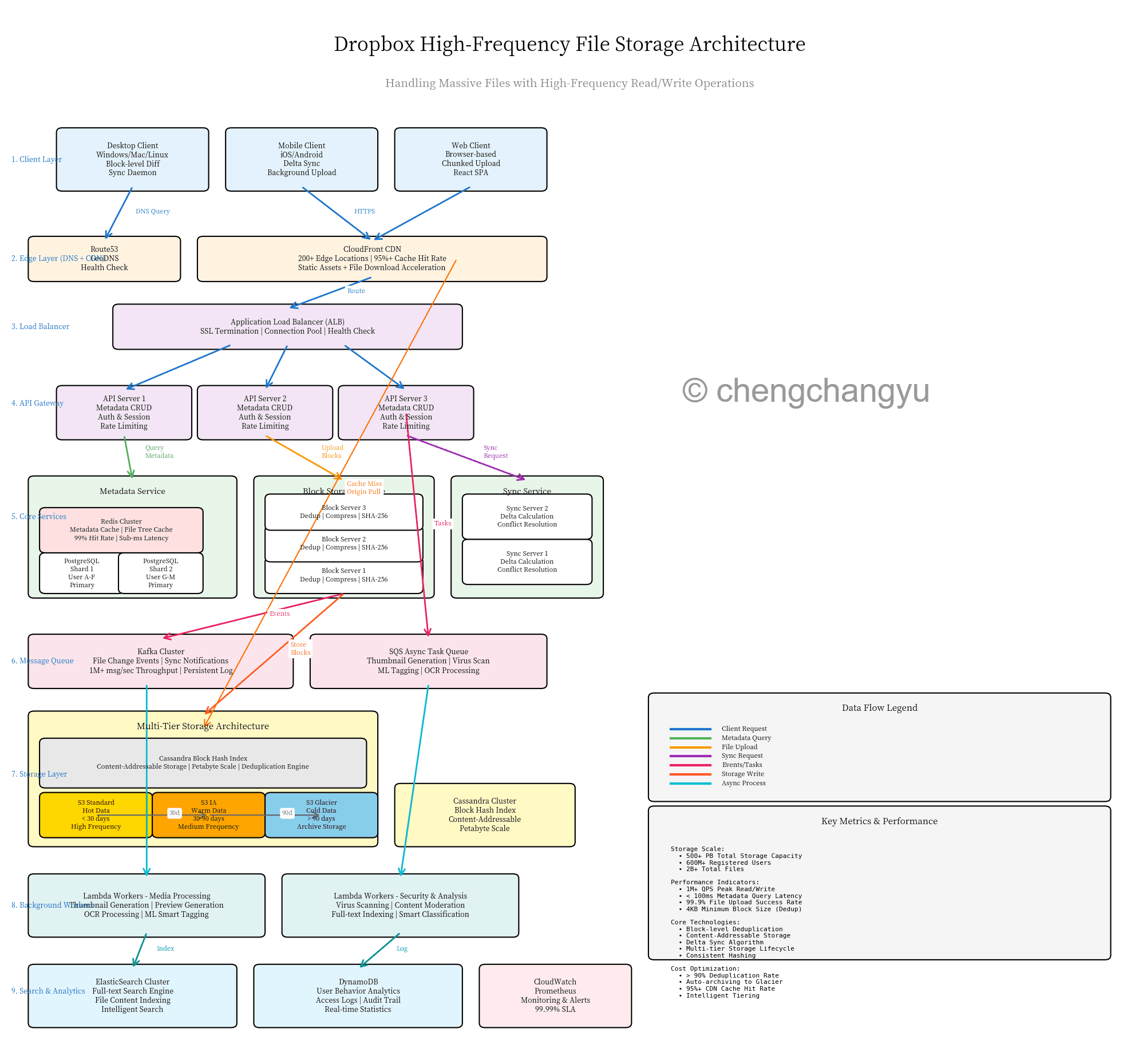
Dropbox High-Frequency File Storage Architecture
The Core Challenge
Dropbox faces a unique set of challenges that most storage systems don't encounter:
- Massive Scale: Billions of files across hundreds of petabytes
- High Frequency: Millions of read/write operations per second
- Real-time Sync: Changes must propagate to all devices instantly
- Cost Efficiency: Storage costs can spiral out of control without optimization
- Global Distribution: Users expect fast access from anywhere in the world
The solution? A sophisticated multi-layered architecture built on several key principles.
Architecture Overview: 9 Layers of Excellence
Layer 1: Client Layer
Dropbox supports three primary client types:
- Desktop Clients (Windows/Mac/Linux): Run a sync daemon that monitors file changes at the block level
- Mobile Clients (iOS/Android): Implement delta sync with background upload capabilities
- Web Clients: Browser-based React SPA with chunked upload support
Each client is optimized for its platform while maintaining consistent sync behavior across all devices.
Layer 2: Edge Layer (DNS + CDN)
Route53 GeoDNS directs users to the nearest regional endpoint based on geographic location and health checks.
CloudFront CDN with 200+ edge locations provides:
- 95%+ cache hit rate for file downloads
- Static asset delivery
- SSL termination at the edge
- DDoS protection
This layer alone reduces origin server load by over 90%.
Layer 3: Load Balancer
Application Load Balancers (ALB) provide:
- SSL termination
- Connection pooling
- Health checks
- Auto-scaling integration
The ALB distributes traffic across multiple API servers in each region, ensuring no single point of failure.
Layer 4: API Gateway
Multiple API servers handle:
- Metadata CRUD operations
- Authentication and session management
- Rate limiting
- Request validation
These servers are stateless, allowing horizontal scaling based on demand.
Layer 5: Core Services
This is where the magic happens. Three specialized services work in concert:
Metadata Service
- PostgreSQL sharding by User ID (e.g., Shard 1: Users A-F, Shard 2: Users G-M)
- Redis Cluster caching with 99% hit rate
- Stores file trees, permissions, sharing metadata
- Sub-millisecond query latency
Block Storage Service
- Handles file chunking and deduplication
- Computes SHA-256 hashes for content addressing
- Compresses blocks before storage
- Achieves 90%+ deduplication rate
Sync Service
- Calculates delta changes between file versions
- Resolves conflicts using timestamp and version vectors
- Coordinates real-time notifications
- Manages version history
Layer 6: Message Queue
Two queue systems handle different workloads:
Kafka Cluster:
- 1M+ messages per second throughput
- File change events
- Real-time sync notifications
- Persistent log for replay
SQS (Simple Queue Service):
- Async task queuing
- Thumbnail generation
- Virus scanning
- ML tagging and OCR
This separation ensures critical sync operations aren't blocked by heavy background processing.
Layer 7: Storage Layer
The storage layer implements a sophisticated multi-tier architecture:
S3 Standard (Hot Data)
- Files accessed within last 30 days
- High-frequency access
- Highest cost per GB, but fastest access
S3 Infrequent Access (Warm Data)
- Files accessed 30-90 days ago
- Medium-frequency access
- 50% cheaper than Standard
S3 Glacier (Cold Data)
- Files older than 90 days
- Archive storage
- 90% cheaper than Standard
- Retrieval time: minutes to hours
Cassandra Block Hash Index:
- Content-addressable storage
- Petabyte-scale indexing
- O(1) lookup for block deduplication
- Distributed across multiple data centers
This tiering strategy alone saves Dropbox millions in storage costs annually.
Layer 8: Background Workers
Lambda workers handle compute-intensive tasks asynchronously:
Media Processing:
- Thumbnail generation for images/videos
- Preview generation for documents
- OCR for scanned documents
- ML-based smart tagging
Security & Analysis:
- Virus scanning
- Content moderation
- Full-text indexing
- Smart classification
These workers scale automatically based on queue depth.
Layer 9: Search & Analytics
ElasticSearch Cluster:
- Full-text search across file contents
- Intelligent search with autocomplete
- Faceted search by file type, date, owner
DynamoDB:
- User behavior analytics
- Access logs and audit trails
- Real-time statistics
- Compliance reporting
CloudWatch + Prometheus:
- System monitoring
- Performance metrics
- Alerting
- 99.99% SLA tracking
The Secret Sauce: Block-Level Deduplication
The most critical optimization in Dropbox's architecture is block-level deduplication. Here's how it works:
The Process
- File Chunking: Files are split into 4KB blocks (optimal size balancing efficiency and overhead)
- Hash Calculation: Each block gets a SHA-256 hash (content fingerprint)
- Dedup Check: Query Cassandra to see if this hash already exists
- Conditional Upload: Only upload blocks that don't exist
- Metadata Linking: Link the file metadata to existing block hashes
The Impact
- 90%+ deduplication rate per user on average
- If you upload a 100MB file that's 90% identical to an existing file, only 10MB is actually stored
- Shared files across users are stored only once
- System updates and common files (like OS installers) are massively deduplicated
This single optimization reduces storage costs by an order of magnitude.
Delta Sync: The Real-Time Magic
When you edit a file on one device, how does it appear on your other devices almost instantly?
The Delta Sync Algorithm
- Local Change Detection: Sync daemon detects file modification
- Block Diff Calculation: Identify which 4KB blocks changed
- Selective Upload: Upload only changed blocks (not the entire file)
- Server Reassembly: Server reconstructs the new file version
- Kafka Notification: Publish change event to message queue
- Client Pull: Other devices receive notification and download only changed blocks
- Local Reassembly: Clients reconstruct the updated file
Example
You edit line 50 in a 10MB document:
- Traditional sync: Upload entire 10MB file
- Delta sync: Upload only the 4KB block containing line 50
- Result: 2,500x less data transferred!
Conflict Resolution Strategy
When two users edit the same file simultaneously, Dropbox employs a sophisticated conflict resolution system:
Automatic Merge
- Non-overlapping changes are merged automatically
- Uses operational transformation algorithms
- Works for text files and structured data
Conflict Copies
- When automatic merge isn't possible, create a "conflicted copy"
- Original file keeps the first-to-server version
- Conflicted copy saved with timestamp and username
- User manually resolves conflicts
Version History
- 30-day version history for all files
- Enterprise plans: Extended or unlimited history
- Point-in-time recovery
- Ransomware protection
Performance Metrics That Matter
Storage Scale
- 500+ PB: Total storage capacity
- 600M+: Registered users
- 2B+: Total files managed
Performance Indicators
- 1M+ QPS: Peak read/write queries per second
- < 100ms: Metadata query latency
- 99.9%: File upload success rate
- 4KB: Minimum block size for optimal deduplication
Cost Optimization
- > 90%: Average deduplication rate
- 95%+: CDN cache hit rate
- Automatic tiering: Moves cold data to cheaper storage
- Intelligent compression: Adapts to file type
Key Design Principles
1. Metadata-Data Separation
Separating metadata (file names, permissions, structure) from actual file data allows:
- Fast directory listings without touching storage
- Efficient search and filtering
- Independent scaling of metadata and data layers
2. Content-Addressable Storage
Using block hashes as identifiers provides:
- Automatic deduplication
- Data integrity verification
- Efficient versioning
- Immutable blocks (no overwrites)
3. Async Processing
Moving non-critical operations to background queues enables:
- Faster user-facing operations
- Better resource utilization
- Graceful degradation under load
- Cost-effective scaling
4. Multi-Tier Storage
Automatically moving data between storage tiers based on access patterns:
- Hot data: Fast, expensive storage
- Warm data: Balanced performance and cost
- Cold data: Cheap archival storage
- Saves millions in infrastructure costs
5. Edge-First Architecture
Pushing content and compute to the edge:
- Reduced latency for global users
- Lower bandwidth costs
- Better user experience
- DDoS protection
Scalability Strategies
Horizontal Scaling
- API Servers: Auto Scaling Groups add/remove instances based on load
- Block Servers: Consistent hashing distributes blocks across servers
- Workers: Lambda functions scale automatically to queue depth
Vertical Scaling
- Cache Layer: Redis Cluster can add nodes without downtime
- Storage Layer: S3 scales infinitely without intervention
- Index Layer: Cassandra adds nodes to increase capacity
Geographic Scaling
- Multi-region deployment: Data centers on every continent
- Cross-region replication: Disaster recovery and data locality
- Edge computing: Process data close to users
Security & Compliance
Data Protection
- Encryption at rest: AES-256 for stored data
- Encryption in transit: TLS 1.3 for all connections
- Zero-knowledge option: Dropbox doesn't have decryption keys (Enterprise)
Access Control
- Fine-grained permissions: Read, write, share controls
- Team policies: Centralized admin controls
- Two-factor authentication: Required for sensitive accounts
Compliance
- Audit logs: Complete activity tracking
- Data residency: Store data in specific regions
- Certifications: SOC 2, ISO 27001, GDPR compliant
Lessons Learned & Best Practices
1. Start Simple, Scale Gradually
Dropbox didn't build this architecture on day one. They started with AWS S3 and gradually built custom solutions as they hit scaling limits.
2. Measure Everything
You can't optimize what you don't measure. Comprehensive metrics and monitoring are essential for identifying bottlenecks.
3. Optimize for the Common Case
90% of file operations are small changes to existing files. Delta sync and block deduplication optimize for this pattern.
4. Design for Failure
Every component can fail. Build redundancy, implement graceful degradation, and test failure scenarios regularly.
5. Cost is a Feature
Storage costs directly impact profitability. Deduplication and intelligent tiering aren't just optimizations—they're business requirements.
Future Directions
AI-Powered Optimization
- Predictive caching: Pre-load files users are likely to access
- Smart compression: Choose algorithms based on file content
- Anomaly detection: Identify unusual access patterns (security)
Edge Computing
- Local processing: Run OCR and thumbnails on edge nodes
- P2P sync: Devices on same network sync directly
- Offline-first: Better support for disconnected scenarios
Blockchain Integration
- Immutable audit logs: Tamper-proof compliance records
- Decentralized storage: Hybrid cloud/blockchain architecture
- Smart contracts: Automated data retention policies
Conclusion
Dropbox's architecture is a masterclass in building scalable, cost-effective storage systems. The key takeaways:
- Block-level deduplication can reduce storage by 90%+
- Metadata-data separation enables fast operations at scale
- Multi-tier storage dramatically reduces costs
- Async processing improves user experience
- Edge-first design serves global users efficiently
Whether you're building a file storage system, a content delivery platform, or any high-scale application, these principles apply. Start with the fundamentals, measure relentlessly, and optimize for your specific use case.
Further Reading
- Dropbox Engineering Blog
- AWS S3 Best Practices
- Consistent Hashing Explained
- Content-Addressable Storage